
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月26日
1分でわかるこの記事の要約 DLPの誤検知は、業務効率低下やセキュリティリスク増大を招くため、適切な対策が不可欠です。 正規表現の厳密な定義、辞書の戦略的運用、体系的な例外管理がDLP精度改善の鍵です。 アンカーや文字ク […]
目次
情報漏洩対策として導入したDLP(Data Loss Prevention)が、誤検知ばかりで業務の妨げになっていませんか?本来守るべき機密情報を保護するためのContent Inspection機能が、正当な業務メールやファイルのやり取りまでブロックしてしまう。このような状況は、セキュリティ担当者の運用負荷を増大させ、本来検出すべき重大なアラートを見逃すリスクを高めます。この記事では、DLPの精度を改善し、誤検知を劇的に減らすための「正規表現」「辞書」「例外」という3つの管理手法を、具体的な設定例を交えて徹底的に解説します。

DLPソリューションは、データ漏洩のリスクから企業を守る強力なツールですが、その運用において誤検知は避けられない課題です。特に、ファイルや通信内容を精査するContent Inspection機能は、設定のチューニングが不十分だと誤検知を頻発させ、情報漏洩対策そのものへの信頼を損なう原因となり得ます。
コンテンツインスペクションにおける誤検知の根本原因は、主に以下の3つの要素に集約されます。これらの原因を理解することが、DLPの精度改善に向けた第一歩となります。
汎用性の高すぎる正規表現 正規表現は特定の文字列パターンを検出する強力な手法ですが、定義が曖昧だと意図しない文字列にまで反応してしまいます。例えば、クレジットカード番号を検出するために「16桁の数字」というルールを設定すると、請求書番号や社員番号といった業務上の単なる数字の羅列まで検知してしまいます。マイナンバーや電話番号の検出においても同様の課題が発生しがちです。
メンテナンスされていない辞書 DLPでは、製品名やプロジェクトコードといった特定のキーワードを辞書に登録し、それらが含まれる文書の流出を監視します。しかし、プロジェクトが終了した後も古いキーワードが辞書に残り続けていると、新しい文書で使われた一般的な単語と偶然一致し、誤検知を引き起こすことがあります。辞書が組織の実態と乖離していくことで、検出精度は徐々に低下していくのです。
硬直化した例外設定 特定の部署や取引先とのやり取りをスムーズにするため、一時的に例外ルールを設けることは珍しくありません。しかし、その例外設定が必要なくなった後も見直されずに放置されると、管理が複雑化するだけでなく、恒久的なセキュリティホールになり得ます。例外が積み重なり、ポリシー全体がブラックボックス化してしまうと、運用は極めて困難になります。
DLPの誤検知を「仕方ないもの」として放置すると、企業は複数の深刻なリスクに直面します。
従業員の業務効率低下 正当なEmail DLPによるメール送信や、Web DLPを介したクラウドストレージへのファイルアップロードがブロックされれば、ビジネスのスピードは著しく損なわれます。
セキュリティ担当者の運用負荷増大 毎日大量の誤検知アラート(ログ)の確認と解除作業に追われることで、担当者は疲弊し、より戦略的なセキュリティ対策に時間を割けなくなります。
「オオカミ少年」状態によるリスクの高まり アラートが鳴っても「また誤検知だろう」と軽視する空気が生まれると、本当に危険なデータ漏洩の兆候を見逃すリスクが飛躍的に高まります。結果として、DLPソリューションそのものへの信頼が失われ、情報漏洩対策が形骸化してしまうのです。
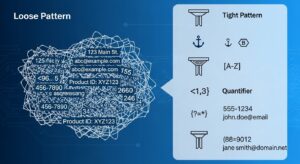
正規表現のチューニングは、DLPの誤検知を減らす上で最も効果的な対策の一つです。少しの工夫で検出精度は劇的に改善します。ここでは、すぐに実践できる具体的なテクニックを紹介します。
誤検知を減らす正規表現の基本は、検出したいパターンの条件をできるだけ厳しく絞り込むことです。そのために有効な3つのテクニックを解説します。
例えば、文書内の「機密」という単語だけを検出したい場合、単に「機密」と設定すると「機密性」といった単語にもヒットします。これを避けるには、単語の境界を示す「\b」を使い、「\b機密\b」と記述します。これにより、「機密」という独立した単語のみを正確に検出できます。
例えば、日本の携帯電話番号を検出する場合、「\d{11}」(11桁の数字)では不十分です。これを「0[789]0-\d{4}-\d{4}」のように、先頭の数字やハイフンの有無をより具体的に定義することで、不要な数字の羅列を除外し、精度を向上させることができます。
これは、特定のキーワードが周辺に存在する場合にのみパターンを検出する高度なテクニックです。例えば、単なる16桁の数字ではなく、「カード番号」や「Credit Card」といった文字列の直後にある16桁の数字のみをクレジットカード番号として検出したい場合に有効です。これにより、文脈を無視した機械的なマッチングによる誤検知を大幅に削減できます。
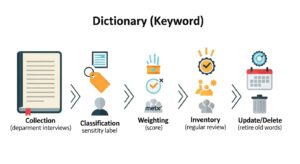
正規表現と並んでDLPのContent Inspectionで重要な役割を担うのが「辞書」です。組織固有の機密情報を守るためには、辞書の戦略的な管理と運用が欠かせません。
精度の高い辞書を維持するためには、作成から廃棄までの一貫したプロセスを確立することが重要です。
各業務部門からプロジェクト名、製品コード、顧客名といった機密情報をヒアリングし、収集します。集めたキーワードは、「極秘」「秘」「社外秘」のような機密度レベルや、部門、プロジェクト単位で分類し、管理しやすくします。
単一のキーワードが検出されただけでアラートを出すと誤検知が増えるため、複数の関連キーワードが同一ファイルやメール内に存在する場合に検知の閾値を引き上げるスコアリング方式を導入します。例えば、「新製品」という単語だけでは低スコアですが、「新製品」「開発コード」「価格表」の3つが揃った文書は高スコアと判断し、より厳しいポリシーを適用する、といった設定です。
四半期に一度など、定期的に辞書の内容を見直し、古くなった情報を削除・更新するプロセスを運用に組み込みます。このレビューには、情報システム部門だけでなく、キーワードのオーナーである事業部門の担当者も参加することが、辞書を常に最新の状態に保つための鍵となります。
辞書のキーワードを登録する際には、「完全一致」と「部分一致」のマッチング方法を選択できますが、この使い分けが精度を大きく左右します。誤検知を減らすための基本原則は、「完全一致を基本とし、部分一致は限定的に使用する」ことです。
例えば、「株式会社」というキーワードを部分一致で登録してしまうと、「株式会社〇〇」という社名だけでなく、本文中に「株式会社」という単語が含まれるすべての文書がヒットしてしまい、誤検知の嵐に見舞われます。部分一致は、特定のキーワードの派生形を網羅的に検出したい場合など、目的を明確にした上で慎重に利用すべきです。ポリシーの目的に応じて最適なマッチング方法を選択する視点が求められます。

DLP運用において、業務上の必要性からポリシーの例外を設定することは避けられません。しかし、その管理を誤ると、DLPは容易に形骸化します。ここでは、セキュリティと利便性を両立させる例外設定の考え方を紹介します。
「急ぎだから」といった理由で場当たり的に例外設定を追加していく運用は、3つの大きなリスクを生みます。
セキュリティホールの恒久化 特定の部署や個人に対して設定した一時的な通信許可が、見直されることなく永続的な抜け道となってしまう危険性があります。
ポリシーの複雑化とブラックボックス化 例外ルールが積み重なると、なぜその設定が存在するのか誰にも分からなくなり、ポリシーの全体像を把握できなくなります。これにより、新たなルールを追加する際の意図しない影響(副作用)を予測することも困難になります。
監査対応の困難化 内部監査や外部監査の際に、特定の設定がなぜ存在するのか、その正当性を説明できなくなります。これは、企業の情報セキュリティガバナンスにおける重大な欠陥と見なされる可能性があります。
安全な例外管理を実現するためには、明確なルールに基づいた体系的な運用が不可欠です。
誰が、どのような目的で、いつまで、どの範囲の例外を必要としているのかを明記した申請書を必須とし、上長やセキュリティ担当者による承認フローを確立します。ワークフローシステムなどを活用して、すべての申請と承認の記録を残すことが重要です。
すべての例外設定には必ず有効期限を設け、「無期限」の許可は原則として禁止します。期限が切れる前に担当者へ自動で通知が届き、延長が必要な場合は再申請・再レビューを必須とする仕組みを構築することで、不要な例外が放置されるのを防ぎます。
例えば、特定のユーザーに対してすべての通信を許可するのではなく、特定の送信先ドメインへのメール送信のみを許可するなど、例外の影響範囲をできるだけ絞り込みます。エンドポイント、ネットワーク、クラウドといったデータが通過するチャネルごとに、最適な例外ポリシーを検討することが、セキュリティレベルを維持する上で極めて重要です。
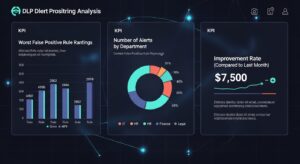
DLPの精度を継続的に改善していくためには、現状を正しく把握することが不可欠です。そのためには、DLPが出力するログを分析し、分かりやすいレポートとして可視化する取り組みが欠かせません。
膨大なアラートログの中から、意味のある知見を引き出すための分析手法をいくつか紹介します。まずは、どのDLPルール(特定の正規表現や辞書のキーワード)が最も多くの誤検知を発生させているかを特定します。この「ワーストランキング」上位のルールから優先的にチューニングを行うことで、効率的に全体の誤検知件数を削減できます。
次に、部門やユーザー単位でアラートの発生件数を分析し、特定の部署で誤検知が多発していないかを確認します。これは、部署特有の業務内容にポリシーが適合していない可能性を示唆しており、ヒアリングや業務フローの見直しにつなげる良いきっかけとなります。SIEMのようなログ統合管理ツールと連携させれば、より高度な相関分析も可能です。
セキュリティ担当者だけが状況を把握していても、全社的な改善は進みません。DLP運用の状況を経営層や事業部門に理解してもらうためには、レポートの内容を工夫する必要があります。
単に「今月の検知件数は〇〇件でした」と報告するのではなく、「チューニングにより、誤検知率が先月比で30%改善しました」「先月は重大な情報漏洩インシデントとなり得た通信を5件ブロックしました」といったように、具体的な成果やビジネスへの貢献度を可視化することが重要です。
また、専門用語を避け、「誤検知削減により、営業部門のメール送信における業務停滞を月間推定20時間削減」のように、ビジネスインパクトの観点から説明することで、DLP運用の重要性や価値が伝わりやすくなります。

Content Inspectionにおける誤検知は、DLP運用の成否を分ける避けては通れない課題です。しかし、これを放置すれば、DLPは宝の持ち腐れどころか、業務の足かせになりかねません。重要なのは、場当たり的な対応ではなく、「正規表現の高度化」「辞書の戦略的な管理」「体系的な例外運用」という3つの軸で、継続的にポリシーをチューニングしていくことです。
この記事で紹介したテクニックを参考に、まずは自社のDLPのログを見直し、最も誤検知が多いルールを特定することから始めてみてください。一つひとつの課題に地道に取り組むことで、DLPの検出精度は着実に向上します。情報漏洩対策と業務効率化を両立させ、データ保護を形骸化させないこと。それが、ゼロトラスト時代に求められる強固なセキュリティ基盤の構築につながるのです。

A1: 少なくとも四半期に一度の定期的なレビューを推奨します。また、組織変更、新規プロジェクトの開始、新しいクラウドサービスの導入など、ビジネス環境に大きな変化があった際は、その都度ポリシーの見直しを行うことが理想的です。常に現状に即したポリシーを維持することが、精度と実用性を保つ鍵となります。
A2: 多くのDLPソリューションには、マイナンバーやクレジットカード番号といった個人情報を検出するための、検証済みの正規表現テンプレートが標準で用意されています。まずはこれらのテンプレートを活用し、その仕組みを理解することから始めるのが効率的です。オンラインには正規表現を試しながら学べるテストツールも多数公開されているので、それらを活用して少しずつ応用範囲を広げていくと良いでしょう。
A3: 残念ながら、誤検知を完全にゼロにすることは現実的ではありません。セキュリティ(より多くの脅威を検出する能力)と利便性(誤検知の少なさ)は、多くの場合トレードオフの関係にあります。DLP運用の目標は、誤検知をゼロにすることではなく、運用に支障がなく、かつ本当に守るべき重要なデータ漏洩を見逃さないレベルまで誤検知の発生を抑制し、管理可能な状態にすることです。
記載されている内容は2026年02月26日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
