
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月26日
1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります。 ルール不全はインシデント見逃し、アラート信頼性低下、セキュリティ投資対効果の低下を招きます。 ロ […]
目次
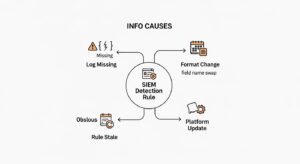
検知ルールが意図した通りに機能しなくなる背景には、複数の要因が複雑に絡み合っています。これらは突然発生するわけではなく、日々のシステム運用の中で静かに進行し、気づいた時にはセキュリティ監視に大きな穴を開けているケースが少なくありません。まずは、検知ルールを無力化してしまう主な原因を深く理解することから始めましょう。
セキュリティ分析の根幹をなすのは、サーバーやネットワーク機器から収集されるログデータです。このログがSIEMに届かなければ、当然ながら検知ルールは機能しません。最も厄介なのが、このログ欠損が「サイレント」、つまり明確なエラー通知なしに発生するケースです。
例えば、ファイアウォールの設定変更ミスでSyslog転送が停止したり、サーバー上のログ転送エージェントがOSアップデート後に異常終了したり、クラウド環境(AWSやAzure)のロギング設定が意図せず変更されたりといった事態が考えられます。これらのログ欠損は、日常的な監視業務の中では見過ごされがちで、インシデントが発生して初めて発覚することも少なくありません。リアルタイムでの脅威検知を目的とするSIEM運用において、ログ欠損は致命的な課題です。
ログ欠損と並んで頻繁に発生するのが、ログの形式変更です。アプリケーションのバージョンアップ、OSのパッチ適用、あるいはログ出力の詳細度設定の変更など、様々な理由でログのフォーマットは変わり得ます。
例えば、「user_id=」で記録されていたフィールドが「account_name=」に変わったり、日時のフォーマットが変更されたりといったケースです。SIEMの検知ルールは、特定のフィールド名や値、正規表現パターンに強く依存しているため、ログ形式がわずかでも変更されると、SIEMのパーサーがデータを正しく構造化できなくなり、ルールが全く機能しなくなるのです。この問題もまた、エラーとして表面化しにくく、検知漏れの原因となります。
ビジネスの成長に伴い、企業のIT環境も絶えず変化します。新しいサーバーの導入、クラウドサービスの利用開始など、システム環境は動的です。このような環境変化に検知ルールが追随できていない場合、ルールは「陳腐化」し、有効性を失います。
例えば、古いIPアドレスセグメントを対象にしたルールのまま放置されていたり、現在は使われていない脆弱性を狙った攻撃を監視し続けていたりするケースです。サイバー攻撃の手法も日々進化しており、数年前に有効だった検知ロジックが現在の脅威には無力である可能性も考えられます。
見落としがちな要因として、SIEMプラットフォーム自体のアップデートに伴う仕様変更があります。SplunkやMicrosoft Sentinel、QRadarといった主要なSIEM製品は、定期的なアップデートが行われます。その過程で、検索コマンドの仕様が変更されたり、データモデルの構造が変わったりすることがあります。これらの変更が、既存の検知ルールやダッシュボードに予期せぬ影響を与え、正常な稼働を妨げる可能性があります。

機能不全に陥った検知ルールを放置することは、単なる「設定ミス」では済みません。企業のセキュリティ体制に深刻な脆弱性を生み出し、ビジネスに多大な損害を与える可能性があります。
最も直接的かつ深刻なリスクは、サイバー攻撃の兆候を見逃してしまうことです。ランサムウェア攻撃の初期侵入や、マルウェアによるC2サーバーとの通信など、本来捉えるべき異常な挙動を検知できなくなります。これにより、攻撃者は活動範囲を広げ、最終的に重大なインシデントを引き起こす可能性があります。検知が遅れれば遅れるほど、被害の規模は指数関数的に増大します。
ルールが壊れると、アラートが出ない「偽陰性(False Negative)」だけでなく、無関係なイベントに反応する「誤検知(False Positive)」の増加にも繋がります。大量の誤検知アラートに日々追われると、運用チームは「アラート疲れ」に陥ります。その結果、本当に重要なインシデントの兆候がノイズに埋もれ、見過ごされるリスクが高まります。
企業は多額のコストを投じてSIEMを導入・運用しています。しかし、中核をなす検知ルールが機能していなければ、この投資は意味をなしません。高価なシステムはただログを貯蔵するだけの箱と化し、脅威検知という本来の目的を果たせなくなります。これは、セキュリティ投資対効果(ROI)を著しく低下させるだけでなく、経営層からの信頼を損なう原因にもなり得ます。
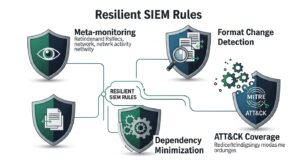
では、どうすれば「壊れやすい」状況から脱却できるのでしょうか。鍵となるのが、障害や変化を前提とした「耐性設計」という考え方です。
検知ルールが機能する大前提は、分析対象のログがSIEMに正常に送信されていることです。これを監視するため、「攻撃を検知するルール」ではなく、「ログ監視システム自体の正常性を監視するルール」、通称「メタ・ルール」を実装します。
例えば、「重要なWebサーバーから過去1時間、アクセスログが1件も届いていない場合にアラートを発報する」といったルールを設定します。これにより、ログ転送エージェントの停止といったログ欠損の事態をリアルタイムで検知し、迅速な対応を可能にします。
ログ形式の変更に起因するルールの機能不全を防ぐには、変更そのものを早期に検知する仕組みが必要です。多くのSIEMには、ログのパース(解釈)に失敗したイベントを記録する機能があります。この「パースエラー」の発生率が急増した場合にアラートを出すルールを設定することで、予期せぬ形式変更を素早く察知できます。また、機械学習(UEBAなど)を活用し、正常なログパターンから逸脱する異常を自動で検知させる方法も有効です。
検知ルールを作成する際は、特定のログ形式やフィールド名に過度に依存しない、柔軟な設計を心掛けることが重要です。例えば、「WindowsイベントID “4625”」といった厳密なルールではなく、「同一IPから短時間に複数の認証失敗イベントが発生」のように、より抽象的で汎用的なロジックにすることで、形式変更への耐性が向上します。複数の異なるログソースを組み合わせた相関分析も、依存度を下げ、信頼性を高める上で有効です。
攻撃者の戦術・技術・手順(TTPs)を体系化した「MITRE ATT&CK」フレームワークの活用は非常に有益です。ATT&CKは、特定の製品やログ形式に依存しない、攻撃者の「行動」に基づいています。例えば、「T1059.001: PowerShell」という攻撃テクニックを、Windowsイベントログ、EDRログ、プロキシログなど複数のデータソースから捉えるルールを設計します。これにより、一つのログソースで問題が発生しても、他でカバーできる可能性が高まり、監視体制全体の防御力を高めます。
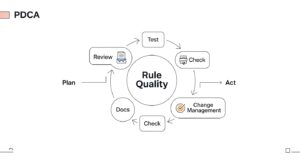
耐性のあるルールを設計しても、それで終わりではありません。その品質を維持するためには継続的な運用プロセスが不可欠です。
検知ルールは一度設定したら放置せず、定期的に有効性を見直す必要があります。最低でも四半期に一度は、全ルールを棚卸しし、「現在も必要か?」「誤検知は多くないか?」「最新の脅威に対応できているか?」といった観点でレビューしましょう。誤検知が多いルールはチューニングし、不要なルールは無効化することで、運用負荷を軽減し、重要なアラートに集中できる環境を維持します。
新しいルールを本番適用する前には、必ず十分なテストと検証を行うべきです。過去のログデータで動作確認を行う「リプレイテスト」や、Atomic Red Teamのようなツールで擬似攻撃を発生させて検知を試す「実地検証」が重要です。近年では、SOARプラットフォームを活用してこれらのテストプロセスを自動化し、ルールの信頼性を高める動きも進んでいます。
ログに関する問題の多くは、部門間の連携不足に起因します。これを解決するため、組織横断的な「変更管理プロセス」を確立することが不可欠です。サーバーの仕様変更やアプリのアップデートなど、ログ出力に影響する全ての変更作業について、事前にセキュリティ運用チームへ通知し、影響を評価する仕組みを構築します。これにより、予期せぬ監視の穴を未然に防ぎます。
「あのルールは〇〇さんしか分からない」という状況は大きなリスクです。担当者の異動や退職で重要な検知ロジックが失われる可能性があります。これを防ぐため、各ルールの目的、ロジック、対応する脅威(MITRE ATT&CKのIDなど)、初動対応手順などを標準フォーマットでドキュメント化し、チーム全員がアクセスできるナレッジベースで共有します。
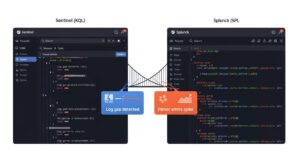
ここでは、具体的なSIEMプラットフォームを例に、耐性設計のアイデアをどう実装できるかを紹介します。
Microsoft Sentinelでは、Kusto Query Language (KQL) を用いてログ欠損を検知するメタ・ルールを簡単に実装できます。例えば、特定のWindowsサーバーからSecurityEventログが30分以上受信されなかった場合にアラートを出すには、以下のようなKQLクエリが考えられます。
SecurityEvent | where TimeGenerated > ago(1h) | summarize LastLog = max(TimeGenerated) by Computer | where Computer == "Server01.contoso.com" and LastLog < ago(30m)
このようなルールを主要なログソースごとに設定することで、監視の健全性を自動で可視化できます。
Splunkでは、強力なサーチコマンドでログの健全性を監視できます。例えば、tstats count where index=firewall by sourcetype, _time span=1h のようなサーチでイベント量の増減を視覚的に把握し、ログ欠損や異常を検知します。
また、index=_internal "Could not extract timestamp" のように、Splunk自身の内部ログを検索することで、タイムスタンプのパースに失敗しているイベント、つまり形式変更の可能性があるログを特定し、アラート通知が可能です。

SIEMの検知ルールは、一度作れば終わりという「静的な設定」ではありません。それは、変化し続けるIT環境と進化するサイバー脅威に対応し続けるための「動的なプロセス」です。
本記事で解説したように、ログの欠損や形式変更を前提とした耐性設計を取り入れ、定期的なレビュー、テスト、組織的な連携といった継続的な運用改善を実践すること。これらを通じて、検知ルールを常に最適な状態に「育てていく」という意識こそが、セキュリティ監視の信頼性と安定稼働を支える基盤となります。まずは自社の検知ルールを見直し、ログのヘルスチェックを行うメタ・ルールの実装から始めてみてはいかがでしょうか。

A1: ルールの重要度によりますが、一般的には四半期に一度の定期的なレビューとテストが推奨されます。ランサムウェアの兆候など、クリティカルなインシデントを検知するルールは、より短い間隔(月次など)での検証が望ましいでしょう。また、システム環境に大きな変更があった際や、新しい脅威情報が公開された際には、都度、関連ルールの有効性を確認することが重要です。
A2: 最も効果的な方法は、本記事でも触れた「変更管理プロセス」を組織内に確立することです。アプリケーションのアップデートやインフラの構成変更を行う際に、セキュリティチームがレビューに参加し、ログへの影響を事前に評価する体制が理想です。技術的な対策としては、ステージング環境で変更を適用した際に、そのログをSIEMに取り込んで既存ルールへの影響をテストする方法も有効です。
A3: はい、有用なオープンソースツールが存在します。例えば、「Sigma」は、様々なSIEMで利用可能な標準フォーマットで検知ルールを記述するプロジェクトで、ルールの共有や管理が容易になります。また、「Atomic Red Team」は、MITRE ATT&CKの各テクニックに対応したテストを実行できるツールで、ルールが実際に機能するかを検証するのに非常に役立ちます。これらの活用で、品質管理の効率化と客観的な評価が可能です。
記載されている内容は2026年02月26日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 サイバー攻撃対策には、限られたリソースで優先順位付けが不可欠であることを認識する。 MITR...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
