
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月26日
1分でわかるこの記事の要約 AIのラベル誤付与は、モデル精度低下やビジネスリスクに直結する深刻な課題です。 原因はガイドラインの曖昧さや作業者のばらつき、AIモデルの限界などが挙げられます。 AIと人間の判断を組み合わせ […]
目次
データラベリングにおける誤付与は、単なる作業ミスに留まらず、ビジネスの根幹を揺るがしかねないリスクを内包しています。
機械学習、特に教師あり学習では、ラベル付けされた「教師データ」の品質がモデルの性能を決定づけます。この教師データに誤ったラベルが含まれていると、AIはそれを「正解」として学習してしまいます。いわゆる「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」状態に陥り、予測モデルの分類精度は著しく低下します。
結果として、原因究明、データの再クレンジング、アノテーションのやり直し、モデルの再学習といった膨大な手戻りが発生し、多大な時間とコストを浪費することになります。
SNSやECサイトなどUGC(ユーザー生成コンテンツ)を扱うサービスでは、コンテンツ検査が企業の社会的責任を果たす上で不可欠です。不適切なコンテンツ(暴力的な表現、差別的な投稿など)に誤ったラベルが付与され、システムをすり抜けて公開された場合、ブランドイメージの毀損だけでなく、法的なコンプライアンス違反や炎上リスクに繋がります。
ラベルの誤付与は、エンドユーザーの体験にも直接的な悪影響を及ぼします。例えば、ECサイトで興味のない商品がレコメンドされたり、ニュースアプリで不快なコンテンツが表示されたりするケースです。このような不適切なデータ分類は、ユーザーにストレスを与え、顧客満足度の低下、ひいてはユーザー離れや解約率の上昇を招き、長期的なビジネス成長を妨げます。
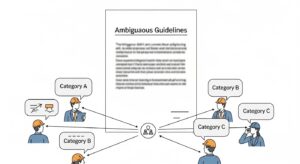
効果的な対策を講じるには、まず発生原因を理解することが重要です。原因は一つではなく、複数の要因が複雑に絡み合っています。
データラベリングの品質を担保する「アノテーションガイドライン」の定義が曖昧だと、作業者ごとに解釈が異なり、ラベルの一貫性が失われます。例えば、「少し攻撃的」なコメントを「不適切」と判断するか否かなど、主観が入りやすい項目の判断基準が明確に言語化・事例化されていないケースが典型です。
人間が作業する以上、スキルレベルや集中力、個人の解釈によるばらつきは避けられません。特に専門知識や文化的背景の理解が必要な領域では、作業者の経験値が品質に大きく影響します。また、長時間の単純作業による疲労もヒューマンエラーを誘発します。
皮肉や風刺、文脈に依存する表現など、AIだけでなく人間でも判断が難しい「エッジケース」は数多く存在します。このような曖昧なコンテンツに無理に一つの正解ラベルを付与しようとすると、誤分類のリスクが高まります。
AIモデルは、学習データに含まれていない新しいパターンや未知のデータに対して、正しく分類できない可能性があります。トレンドや言葉遣いは常に変化するため、一度構築したモデルを放置せず、定期的に新しいデータで再学習させ、性能を検証し続ける運用が不可欠です。

ラベル誤付与対策において、AIによる自動推定(自動ラベリング)は非常に強力なツールです。メリットと限界を正しく理解し、運用することが成功の鍵となります。
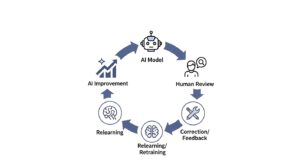
AI自動推定の限界を補い、分類精度を飛躍的に向上させるアプローチが、「ユーザー修正」を取り入れた「ヒューマンインザループ(Human-in-the-Loop: HITL)」です。
ヒューマンインザループとは、AIによる自動化プロセスの中に、意図的に人間の判断やフィードバックを組み込む仕組みのことです。AIの強み(高速・大量処理)と人間の強み(文脈理解・曖昧さの判断)を組み合わせ、システム全体の精度と信頼性を高めます。
ユーザー修正がもたらす3つの価値
効果的なHITLを実現するには、ユーザー修正のフィードバックをシームレスにAIの学習サイクルに組み込む仕組みが重要です。ユーザーが修正したデータを蓄積し、定期的にAIモデルの再学習(ファインチューニング)を自動実行します。このサイクルを回し続けることで、運用すればするほどAIが賢くなる、自己改善型のシステムが実現します。
AI自動推定とユーザー修正を組み合わせた、効果的な運用ワークフローを5つのステップで解説します。
誰が読んでも同じ判断ができるよう、具体的なOK/NG事例を含む明確なラベリングガイドラインを定義します。作業者へのトレーニングや、定期的に複数人で判断基準を合わせる「キャリブレーション」を実施し、品質管理体制を強化します。
対象データにAI予測モデルを適用し、ラベルを自動付与します。この時、分類結果に対する「信頼度スコア(Confidence Score)」を算出することが極めて重要です。これはAIがその分類にどれだけ自信があるかを示す数値で、人間がレビューすべきデータを効率的に絞り込むために活用します。
「信頼度スコアが低いデータ」(例:スコア70%未満)を抽出し、優先的に人間がレビューします。AIが迷ったデータを重点的に確認・修正することで、効率的に全体の精度を向上させます。また、信頼度スコアが高いデータも一定割合でランダムに抽出し、スポットチェックすることで、AIモデルの未知の弱点を発見できます。
サービスの利用者や業務担当者が誤分類を発見した際に、簡単に修正・報告できるインターフェースを用意します(例:「このラベルは間違いですか?」ボタン)。現場の知見を持つユーザーからのフィードバックは、貴重な情報源となります。
Step3とStep4で収集した、人間による修正済みの「質の高いデータ」を教師データとして蓄積し、定期的にAIモデルを再学習させます。このサイクルを繰り返すことで、AIの自動分類精度が継続的に向上し、運用全体の効率化とコスト削減に繋がります。

ラベル誤付与対策は、様々な技術の組み合わせで実現されます。
不適切な画像(暴力的、成人向けなど)の検出、商品画像のカテゴリ分類、顔認識による本人確認(eKYC)などで広く活用されます。AIの誤検知や検知漏れを防ぐために、人間によるレビューと修正のワークフローが不可欠です。
カスタマーサポートへの問い合わせ内容の自動分類、SNS上の誹謗中傷やスパムコメントの検出、記事のトピック分類などに用いられます。文脈やニュアンスの理解が重要なため、ヒューマンインザループによる精度向上が特に効果的です。
「特定の単語が含まれたらNG」といった明確な基準は「ルールベース」で処理し、複雑で曖昧な判定は「機械学習」に任せるなど、両者を組み合わせることで処理全体の効率と精度を両立できます。
近年、高度なデータラベリングやコンテンツ検査の仕組みをSaaSとして提供するAIプラットフォームやクラウドサービスが増えています。アノテーションツール、AIモデル、レビューワークフロー管理機能などを包括的に提供しており、導入のハードルを大幅に下げることができます。

システムを実際に運用する上で、技術面以外にも考慮すべき重要なポイントがあります。
運用上の重要ポイント

AIによるデータ分類において「ラベルの誤付与」は避けて通れない課題です。しかし、この課題はAI自動推定の「効率性」と、人間の判断による「ユーザー修正」の正確性を組み合わせることで、効果的に解決できます。
本記事で解説した「ヒューマンインザループ」の考え方に基づき、AIと人間が協調する運用ワークフローを構築することで、データ品質を継続的に向上させ、機械学習モデルの性能最大化、コンプライアンスリスクの低減、優れたユーザー体験の提供を実現しましょう。

Q1: ヒューマンインザループの導入コストはどのくらいですか?
A1: コストは、対象データの量や複雑さ、求める精度、レビュー人員の確保方法(内製/外注)、利用するツールによって大きく変動します。最初はAIが判断に迷った一部のデータのみを人間がレビューする形からスモールスタートすると、コストを抑えつつ効果を検証できます。多くのSaaSツールは使用量に応じた料金体系のため、初期投資を抑えて導入可能です。
Q2: どのようなデータに対してAIによる自動推定は有効ですか?
A2: 判断基準が明確で、過去に十分な量の正解データが存在するタスクに特に有効です。例えば、商品画像のカテゴリ分類、スパムメールの判定、定型的な問い合わせの振り分けなどが挙げられます。一方で、法的解釈や倫理的判断が求められる複雑なタスクは、依然として人間の判断が中心となります。
Q3: ユーザー修正のフィードバックはリアルタイムでAIモデルに反映されますか?
A3: 一般的にはリアルタイムではありません。一つの修正データだけを学習させるとモデルが過学習(特定のデータに最適化されすぎること)を起こす可能性があるためです。通常は、修正データを一定量蓄積し、バッチ処理でまとめて再学習させるアプローチが取られ、モデルの安定性を保ちながら継続的な精度向上を実現します。
記載されている内容は2026年02月26日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
