
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月26日
1分でわかるこの記事の要約 SOAR導入の失敗は、過剰な期待、連携不足、運用体制のミスマッチが主な原因です。 過剰な自動化は誤検知や設定ミスにより、業務停止という最悪のシナリオを引き起こす可能性があります。 SOAR導入 […]
目次
SOAR(ソアー)とは?
SOARとは、「Security Orchestration, Automation and Response」の略称です。日本語では「セキュリティのオーケストレーション、自動化、および対応」と訳され、セキュリティ運用における3つの主要な機能を統合したソリューションを指します。

SOARは、セキュリティ運用における様々なタスクを自動化し、インシデント対応の迅速化と効率化を実現する夢のようなツールに見えます。しかし、その強力さゆえに、計画や準備が不十分だと深刻な問題を引き起こす可能性があります。多くの組織が直面する、SOAR導入における典型的な課題を3つの観点から見ていきましょう。
SOARを「導入すれば全てが解決する魔法の杖」のように捉えてしまうのは、失敗への第一歩です。インシデント対応のプロセスが標準化されていない状態で、いきなり高度な自動化を目指すと、必ずと言っていいほど壁にぶつかります。どのような脅威に、どのような手順で対応するのか、という組織としての対応方針(プレイブックの原型)がなければ、SOARは何を自動化すれば良いのか判断できません。
また、自動化する業務範囲の定義が曖昧なままプロジェクトを進めてしまうケースも散見されます。まずはどのインシデントから対応を自動化するのか、その効果はどれくらい見込めるのか、といった具体的な目標設定と綿密な計画が不可欠です。この初期計画を怠ると、導入プロジェクトが迷走し、期待した効果が得られないまま頓挫してしまうリスクが高まります。
SOARの真価は、SIEM、EDR、脅威インテリジェンスフィードなど、既存の様々なセキュリティツールとシームレスに連携することで発揮されます。しかし、この「連携」が思った以上に複雑で、失敗の原因となることが少なくありません。
各ツールが持つAPIの仕様が異なったり、バージョンアップによって連携が取れなくなったり、そもそもAPIが提供されていなかったりするケースもあります。これらの技術的な課題を乗り越えるためには、高度な専門知識と開発スキルが必要になる場面も。また、ツール間のデータ形式の違いを吸収するための「翻訳」作業も発生します。この連携部分の作り込みが甘いと、いざインシデントが発生した際にSOARが正常に機能せず、初動対応の遅れに繋がってしまいます。
SOARは一度導入すれば終わり、というツールではありません。むしろ、導入してからが本格的な運用のスタートです。サイバー攻撃の手法は日々進化しており、それに対応するためには、自動化のシナリオである「プレイブック」を常に最新の状態に保つ必要があります。
この継続的な見直しと改善を行うためには、セキュリティの専門知識はもちろん、SOAR製品を使いこなし、時にはスクリプトを記述できるような技術スキルを持った人材が不可欠です。しかし、多くの組織ではこうしたスキルを持つ人材が不足しており、導入したはいいものの、プレイブックが陳腐化してしまい、宝の持ち腐れになっているケースが見られます。SOARを効果的に運用し続けるためには、それを支えるSOCチームの体制構築と、継続的なスキルアップが重要な課題となります。

SOARの導入失敗の中でも、最も深刻なのが「過剰な自動化」によって引き起こされる業務停止です。良かれと思って設定した自動化が、ビジネスに致命的な影響を与えるとは、一体どういうことなのでしょうか。その具体的な原因を紐解いていきます。
インシデント対応における封じ込め策として、感染が疑われる端末をネットワークから自動的に隔離(Quarantine)するプレイブックは非常に有効です。しかし、このトリガーとなるアラートが「誤検知」であった場合、事態は一変します。
例えば、EDRが正常な業務アプリケーションの挙動をマルウェアと誤検知してしまったとします。このアラートをトリガーにSOARが自動で動き出し、営業部門の全PCや、会社の基幹システムが稼働する重要なサーバーを次々とネットワークから隔離してしまったらどうなるでしょうか。社員は業務ができなくなり、場合によっては顧客へのサービス提供も停止してしまうでしょう。人の判断を介さずに、検知ツールのアラートを100%信頼して強力な対処(隔離)を実行する設定は、このようなシステム停止のリスクを常に内包しているのです。
SOARは、マルウェアの除去や不正な設定の修正といった、より踏み込んだ対応(Remediation)も自動化できます。これはインシデントからの迅速な復旧に貢献しますが、一歩間違えればシステムを破壊しかねない諸刃の剣です。
よくある失敗例が、自動修正スクリプトの設定ミスです。例えば、マルウェアが作成した特定のレジストリキーを削除するプレイブックを設計したとします。しかし、そのキーの指定条件が曖昧だったために、OSの動作に必要な正常なレジストリまで削除してしまい、サーバーが起動しなくなった、というケースが考えられます。また、脆弱性のあるファイルを自動で削除する設定が、意図せずシステムの中核ファイルを消してしまい、アプリケーションが動作不能に陥ることもあります。このような自動修正は影響範囲が大きいため、特に慎重な計画とテストが求められます。
SOARの強力な連携機能が、逆に仇となるケースもあります。あるツールでのアクションが別のツールのアクションを呼び、それがまた元のアクションを呼ぶ…といった「自動化の無限ループ」に陥ってしまうのです。
このようなループが発生すると、各ツールに膨大な負荷がかかり、システム全体のパフォーマンスが著しく低下する可能性があります。 また、あるインシデント対応のために実行した自動化が、別のシステムに予期せぬ影響を与えることもあります。特定のポートを自動で閉鎖する対応が、実は他の重要な業務システムで使われているポートだった、というような設定ミスは、複雑な環境では十分に起こり得るリスクです。
では、どうすればSOARの失敗、特に業務停止という最悪の事態を避けることができるのでしょうか。ここでは、計画段階から実際の運用フェーズまで、各段階で実践すべき具体的な防止策を7つご紹介します。
いきなり全てのインシデント対応を完全に自動化しようとするのは無謀です。まずは、影響範囲が限定的で、かつ手作業で行うと時間のかかる定型的なタスクから自動化を始める「スモールスタート」を徹底しましょう。
例えば、フィッシングメールが疑われるアラートに対して、送信元IPアドレスやURLの評判を脅威インテリジェンスと連携して自動で調査し、その結果をチケットに追記する、といった情報収集(エンリッチメント)の自動化から始めるのが良いでしょう。この段階では、システムに直接変更を加えるアクションは行わないため、リスクを最小限に抑えられます。小さな成功体験を積み重ねながら、徐々に自動化の範囲を広げていくことが、失敗しないための鉄則です。
プレイブックを作成したら、本番環境に適用する前に、必ずテスト環境で徹底的に検証することが重要です。実際のインシデントを模したシナリオを用意し、プレイブックが意図した通りに動作するか、各ツールとの連携に問題はないかを確認します。
特に、端末の隔離(Quarantine)や設定の修正(Remediation)といった、システムに影響を与える可能性のあるアクションについては、様々なパターンを想定したテストが必要です。誤検知が発生した場合にどうなるか、対象の端末がオフラインだった場合に処理がどうなるかなど、異常系のテストも念入りに行いましょう。このテストプロセスを軽視することが、設定ミスによる誤作動やシステム停止の直接的な原因となります。
SOARの目的は「完全無人化」ではありません。「人の判断が必要な、より高度な作業に集中できるようにすること」です。したがって、リスクの高いアクションを実行する前には、必ずSOCアナリストの承認を挟むワークフローを設計することが極めて重要です。
例えば、「マルウェア感染が疑われる端末を検知した場合、SOARは自動で関連情報を収集・分析する。しかし、最終的なネットワークからの隔離を実行する前には、SlackやTeamsに通知を送り、アナリストが『承認』ボタンを押すまでは処理を待機させる」といった仕組みです。これにより、誤検知による過剰な対応を防ぎ、自動化の恩恵を受けつつも、安全性を確保することができます。どのポイントで人の判断を介在させるか、という判断基準を組織内で明確に定めておくことが求められます。
特に、役員のPCや基幹サーバーといったビジネスクリティカルな資産に対する対処は、完全自動化すべきではありません。インシデントの重要度(クリティカリティ)に応じて、承認フローを多段階にするなどの工夫も有効です。例えば、一般社員のPCであれば担当アナリストの承認のみで良いが、サーバーであればSOCリーダーの承認も必要とする、といったルールをプレイブックに組み込むことで、リスクコントロールの精度を高めることができます。
SOARはセキュリティ運用を監視するツールですが、そのSOAR自体の動作もまた、監視の対象としなければなりません。SOARが短時間に異常な数のアクションを実行していないか、特定のアラートに対してプレイブックがループしていないか、といった点を監視する仕組みを構築しましょう。
多くのSOAR製品には、実行されたアクションのログやダッシュボード機能が備わっています。これらの機能を活用し、SOARの稼働状況を定常的にチェックする体制を整えることが重要です。万が一、意図しない動作が発生した場合でも、早期に検知し、手動でプレイブックを停止させるなどの介入ができれば、被害を最小限に食い止めることができます。
どれだけ入念に準備やテストをしても、予期せぬトラブルによって業務停止が発生する可能性をゼロにすることはできません。そのため、万が一の事態に備えた復旧計画(インシデントレスポンスプラン)を事前に策定し、手順書として整備しておくことが不可欠です。
SOARによる自動化で問題が発生した場合、どのプレイブックを、どの順番で停止させるのか。隔離された端末やサーバーを、どのようにして正常な状態に戻す(ロールバックする)のか。誰がその判断を行い、誰に報告するのか。これらの手順を明確に文書化し、関係者間で共有しておきましょう。実際に障害が発生した際に、冷静かつ迅速に対応できるかどうかは、この事前準備にかかっています。
一度作成したプレイブックが、未来永劫有効であり続けることはありません。新しいサイバー攻撃の手法が登場したり、社内のシステム環境が変化したり、連携しているツールの仕様が変更されたりすることで、プレイブックは容易に陳腐化します。
したがって、少なくとも四半期に一度、あるいは重要な脅威情報やシステム変更があったタイミングで、定期的にプレイブックの内容を見直し、改善していくプロセスを運用に組み込むことが重要です。この継続的なメンテナンスを怠ると、いざという時にプレイブックが役に立たないばかりか、古い情報に基づいて誤った対応を行い、事態を悪化させるリスクさえあります。
最終的にSOARを使いこなし、その価値を最大限に引き出すのは「人」です。SOCチームのメンバーが、SOARの機能やプレイブックの構造を深く理解している必要があります。また、自動化されたプロセスの中で発生するアラートの意味を正しく解釈し、人の判断が求められる場面で的確な意思決定を下せるだけの、高度なセキュリティ知識も不可欠です。
製品ベンダーが提供するトレーニングへの参加や、定期的なインシデント対応演習(サイバー訓練)などを通じて、チーム全体のスキルセットを継続的に向上させていく投資を惜しんではいけません。ツールを導入するだけでなく、それを扱う人材を育成することも、SOAR運用の成功における重要な要素なのです。
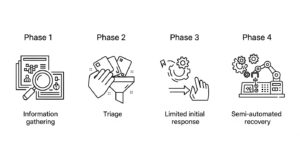
SOAR導入の失敗を防ぐには、スモールスタートと段階的なアプローチが鍵となります。ここでは、リスクを管理しながら着実に自動化を進めていくための、4つのフェーズに分けたベストプラクティスを紹介します。
最初のステップは、システムに直接的な変更を加えない、安全な範囲の自動化から始めることです。具体的には、SIEMやEDRから上がってきたアラートに対し、関連情報を自動で収集・付与(エンリッチメント)するプレイブックを作成します。 例えば、アラートに含まれるIPアドレス、ドメイン、ハッシュ値などを抽出し、脅威インテリジェンスデータベースと自動で照合。その結果(危険度、関連する攻撃者グループなど)をインシデント管理システムのチケットに追記するといったタスクです。これにより、アナリストは手作業での情報収集から解放され、初動調査の時間を大幅に短縮できます。このフェーズでは、業務停止のリスクはほぼありません。
情報収集が自動化できたら、次はインシデントの優先順位付け(トリアージ)や分析を支援する自動化に進みます。エンリッチメントで得られた情報や、組織内での資産の重要度などを基に、インシデントの危険度を自動でスコアリングします。 例えば、「重要サーバー」かつ「既知のマルウェアファミリー」という条件が揃ったアラートは「高」、「一般端末」かつ「レピュテーション不明なIPアドレス」への通信は「中」といった具合に、プレイブック内で判定ロジックを組みます。これにより、アナリストは大量のアラートの中から、まず対応すべき重要なインシデントに集中できるようになります。この段階でも、まだシステムへの直接的な変更は行いません。
ここから、システムに影響を与えるアクションの自動化に着手します。ただし、その適用範囲は厳密に限定する必要があります。例えば、「危険度が『高』と判定され、かつマルウェアの挙動が特定のパターンに100%合致した場合に限り、対象端末のネットワークを隔離(Quarantine)する」といった、非常に確度の高いシナリオに限定して自動化を試みます。
このフェーズでは、前述の「人の判断の介在」を必ず組み込むべきです。自動隔離を実行する前に、必ずアナリストへの承認を求めるステップを挟むことで、誤検知による影響を防止します。限定的ながらも封じ込めを自動化することで、脅威の横展開を迅速に防ぐ効果が期待できます。
最終フェーズは、マルウェアの除去や設定の修正(Remediation)といった、インシデントからの復旧に関わるアクションです。このフェーズは、システムへの影響が最も大きいため、最も慎重に進める必要があります。 完全な自動化を目指すのではなく、「半自動化」に留めるのが現実的です。例えば、SOARが修正に必要なスクリプトを自動で生成し、実行準備までを整える。しかし、そのスクリプトを最終的に実行する権限は、経験豊富な上級アナリストにのみ与える、といった形です。復旧プロセスを可能な限り効率化しつつも、最後の引き金は必ず人が引く、という運用が、安全性を担保する上で非常に重要になります。

SOARは、セキュリティ運用の効率化と高度化を実現するための極めて強力なツールです。しかし、その導入と運用は決して簡単な道のりではありません。特に「過剰自動化」は、良かれと思って設定した機能が、誤検知や設定ミスをきっかけに正常な業務システムまで停止させてしまうという、深刻なリスクをはらんでいます。
この最悪のシナリオを回避する鍵は、本記事で解説した通り、以下の3点に尽きます。
SOARは魔法の杖ではなく、使い手の戦略とスキルが問われる専門的な武器です。その特性を正しく理解し、計画的かつ慎重に導入・運用を進めることで、初めてその真価を発揮します。これからSOAR導入を検討する組織は、まず自社のインシデント対応プロセスを可視化し、どこから自動化に着手すべきかという計画を立てることから始めてみてください。それが、SOAR導入の失敗を防ぎ、成功へと導くための最も確実な第一歩となるでしょう。

A1: 最も注意すべきは、隔離(Quarantine)や修正(Remediation)といった、システムに直接変更を加えるアクションのトリガー条件に関する設定ミスです。検知ツールからのアラートを無条件に信頼し、誤検知の可能性を考慮せずに強力な対処を自動実行する設定は、業務停止に直結する非常に高いリスクを伴います。特に、対象を指定する条件(IPアドレス、ホスト名、ファイルパスなど)が曖昧だと、意図しない範囲にまで影響が及ぶ可能性があるため、細心の注意が必要です。
A2: まず、本番環境と隔離されたテスト環境を用意することが理想です。その上で、①正常系テスト(意図した通りに動作するか)、②準正常系テスト(対象端末がオフラインの場合など)、③異常系テスト(誤検知アラートを意図的に投入するなど)の3つの観点で検証します。具体的には、テスト用のアラートをSIEMなどから送信し、プレイブックが起動することを確認。各ステップが正しく実行され、連携ツールに意図したデータが渡っているかをログで追跡します。特に、システム変更を伴うアクションは、テスト用の端末やサーバーに対してのみ実行されるように厳密に制御し、影響範囲を限定して行う必要があります。
A3: 技術的には可能ですが、推奨されません。完全に自動化された運用(いわゆる「Lights-out SOC」)は、誤検知や未知の攻撃に対する柔軟性を欠き、前述したような業務停止のリスクを常に抱えることになります。ベストプラクティスとしては、定型的でリスクの低いタスク(情報収集、チケット起票など)は完全自動化し、インシデントの分析や対処の意思決定といった高度な判断が求められる部分には、必ず経験豊富なアナリストが介在する「ハイブリッドな運用」を目指すべきです。SOARの目的は人手の排除ではなく、人がより価値の高い仕事に集中できる環境を作ることにあると考えるのが良いでしょう。
記載されている内容は2026年02月26日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
