
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月18日
1分でわかるこの記事の要約 データ分類の課題をAIによる「推定アプローチ」で解決します。 教師なし・半教師あり学習を活用し、アノテーションコストを大幅削減できます。 AIでデータガバナンスを強化し、DLPの誤検知を減らし […]
目次

デジタルトランスフォーメーション(DX)が企業の競争力を左右する現代において、データの戦略的活用は避けて通れないテーマです。その根幹をなすのが、保有するデータを正しく整理・分類するプロセスですが、ここには多くの課題が潜んでいます。
ビジネスの現場では、日々、メール、チャット、議事録、契約書、技術文書、顧客からの問い合わせといった「非構造化データ」が爆発的に増加しています。これらのデータには、ビジネスを成長させるための貴重なインサイトや、保護すべき重要な情報(個人情報、機密情報など)が埋もれています。しかし、テキストや画像、音声といった形式が定まっていない非構造化データは、手作業での分類やタグ付けではデータ量の増加に全く追いつきません。結果として、多くの企業でデータは「塩漬け」状態となり、活用されることなくストレージコストだけが増え続けるという悪循環に陥っています。
これまでデータ分類の中心であったのは、人間による手作業でのラベリングや、特定のキーワードに基づく「ルールベース」のアプローチでした。しかし、これらの従来手法は現代のデータ環境において深刻な課題を抱えています。
GDPRや改正個人情報保護法など、世界的にプライバシー保護の規制は強化されています。企業は、どのような個人情報がどこに保管されているかを正確に把握・管理する責任を負っており、高精度なデータ分類が不可欠です。また、DLP(Data Loss Prevention)のようなセキュリティ対策を効果的に運用する前提としても、保護対象となる重要データが正確に分類されている必要があります。これらの高度な要請に、従来の手法だけで応え続けるのは、もはや現実的ではありません。

従来手法の限界を乗り越える鍵、それがAIによる「推定」アプローチです。これは、すべてのデータに完璧な正解ラベル(教師データ)を与えることを前提とせず、機械学習モデルの能力を最大限に活用して、効率的かつ高精度な自動分類を実現する考え方です。
AI、特に機械学習で最も広く使われる「教師あり学習」は、人間が正解ラベルを付けた大量の「教師データ」をAIに学習させる手法です。スパムフィルターなどが代表例で高い精度を期待できますが、質の高い教師データを大量に用意するという大きな壁があります。アノテーションには莫大なコストと時間がかかり、人的ミスも避けられません。完璧な教師データを求める理想は、実務上の大きな負担となりがちです。
「ラベリングを強制しない」推定アプローチは、この教師データの呪縛から私たちを解放します。その中心技術が「教師なし学習」と「半教師あり学習」です。
Content Inspection(データの中身の検査)において、「推定」は決定的な役割を果たします。例えば、ある文書に「個人情報が含まれている可能性が高い」とAIが推定すれば、その文書を優先的に確認したり、自動でアクセス権限を制限したりできます。すべての文書に完璧なラベルを付けるのではなく、リスクや重要度の「確からしさ」を推定し、その度合いに応じてアクションを変えるのです。これにより、圧倒的な効率化とコスト削減、そして人間では見逃しがちなパターン発見による精度向上が期待できます。
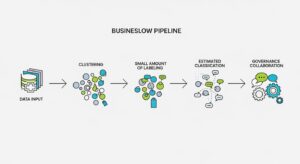
概念を理解したところで、次に推定アプローチを実務に落とし込むための具体的な手法を見ていきましょう。
プロジェクトの第一歩として、「クラスタリング」が非常に有効です。大量の非構造化データ(ラベルなし)をAIにかけることで、内容の類似度に基づき「契約書関連」「技術仕様書」「議事録」といった塊に自動でグループ分けします。人間がその結果を解釈し、各クラスターに代表的なタグを付けるだけで、効率的にデータ全体の構造を把握し、メタデータを作成できます。
精度を高める段階では「アクティブラーニング」が効果的です。これは、AIが「どのデータにラベルを付ければ、最も効率的に賢くなれるか」を自ら判断し、人間に問いかけてくるアプローチです。AIが判断に迷うデータだけを人間がラベリングするため、闇雲に作業するよりはるかに効率的です。この「AIとの対話」を繰り返すことで、最小限のコストでモデルの精度を飛躍的に向上させることができます。
BERTやGPTといった大規模言語モデル(LLM)の登場により、AIは文章の表面的なキーワードだけでなく、文脈やニュアンスまで深く理解できるようになりました。例えば、「契約を破棄する」と「契約を破棄しないように注意する」という文の意味の違いを正確に識別できます。個人情報の検出においても、単語だけでなく文脈から個人情報かどうかを推定するため、DLPの誤検知を大幅に減らし、本当に重要なアラートだけを通知する、といった洗練された運用が実現します。
強力な技術も、正しく導入・運用しなければ効果は出ません。成功のための4つのステップを紹介します。
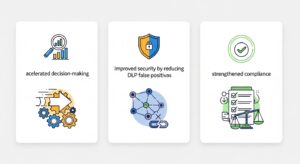
正しく導入された推定ベースの自動分類は、企業全体に大きなビジネスインパクトをもたらします。
AIデータ分類がもたらす3つのビジネスインパクト

本記事では、手作業のラベリングから脱却し、AIによる「推定」を活用してデータ分類を自動化・最適化する実務戦略を解説しました。このアプローチの核心は、完璧な正解ラベルを追い求めるのではなく、AIの能力を最大限に引き出し、コスト、精度、スピードのバランスを取りながら継続的にプロセスを改善していく点にあります。
ラベリングを「強制」するのではなく、AIの「推定」を賢く利用し、人間はより創造的で戦略的な業務に集中する。これこそが、DX時代におけるデータ管理のあるべき姿です。まずはこの記事で紹介したPoCからスモールスタートし、データ活用の新たなステージを目指してみてはいかがでしょうか。
A1: 精度はデータの種類や品質、モデルの学習状況によりますが、適切に運用されたシステムでは人間による作業と同等以上の精度を達成可能です。特にアクティブラーニングなどで継続的にモデルを改善すれば、精度95%以上も珍しくありません。ビジネス目的を達成するために十分な精度を定義し、管理していくことが重要です。
A2: 近年はGUIベースで操作できるクラウドAIサービスも多く、専門家でなくても基本的な仕組みは導入可能です。しかし、分類ポリシーの策定や結果の評価には、業務を深く理解している担当者の関与が不可欠です。技術的なハードルは下がりつつありますが、成功には技術と業務の両面からのアプローチが重要となります。
A3: 多くの自動分類ツールやサービスは、APIを介して外部システムと連携できるよう設計されています。例えば、文書管理システムと連携してファイルのタグ付けを自動化したり、DLPが検知したファイルをAIで再検査して誤検知か判定したり、といった連携が可能です。導入検討時には、APIの仕様などを事前に確認することが重要です。
記載されている内容は2026年02月18日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
