
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月13日
1分でわかるこの記事の要約 RMM(Remote Monitoring and Management)は、IT資産のリモート監視と管理を統合的に行うプラットフォームです。 従来の監視ツールと異なり、RMMは問題検知後の自 […]
目次
従来の監視ツールは問題の「検知」はできても「解決」はしてくれません。この状況を打破する鍵が、RMM(Remote Monitoring and Management)とその中核機能である「自動復旧(セルフヒーリング)」です。
本記事では、RMMを単なる監視ツールで終わらせず、プロアクティブなIT運用を実現するための自動復旧の設計思想から具体的なシナリオまでを徹底解説します。
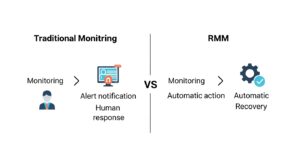
まず、RMMの基本を理解することから始めましょう。RMMは、多くのIT運用担当者が慣れ親しんでいる「監視ツール」とは一線を画すソリューションです。その違いを正しく理解することが、運用自動化への第一歩となります。
RMMとは、その名の通り「リモートでの監視と管理」を行うための統合プラットフォームです。社内ネットワーク内外に存在するサーバー、PC、スマートフォン、ネットワーク機器といったあらゆるIT資産(エンドポイント)を一元的に管理し、その状態を可視化します。主な機能は多岐にわたります。
RMMの主要機能
このように、RMMはエンドポイント管理の要件を幅広くカバーする統合的なツールなのです。
従来の監視ツールの役割は、システムに異常が発生したことを「通知」するまででした。その後の原因調査、復旧作業はすべて人間の手で行う必要があり、いわば「事後対応型」の運用です。
一方、RMMの真価は「検知」した後の「アクション」を自動化できる点にあります。例えば、「特定のサービスの停止を検知したら、自動的にサービスを再起動する」といった設定が可能です。これは、単なる監視から一歩進んだ「管理」、さらにはシステム自身が問題を解決する「自律運用」へのシフトを意味します。
障害が発生してから人間が動くのではなく、障害の予兆を捉えてシステムが自律的に対処する。このプロアクティブなアプローチこそが、RMMがITインフラ運用にもたらす最大の価値であり、運用負荷の劇的な軽減とサービスの安定性向上を実現するのです。
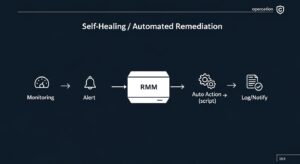
RMMの価値を最大化する機能、それが「自動復旧(セルフヒーリング)」です。この概念を理解し、自社の運用に組み込むことで、IT運用は大きく変わります。
セルフヒーリングとは、システムが自身の問題を検知し、あらかじめ定義された手順に従って自己修復する仕組みを指します。IT運用の文脈における自動復旧プロセスは、主に以下の3つのステップで構成されます。
この一連の流れが人手を介さずに自動で完結することで、システムはまるで自己治癒能力を持ったかのように、安定した状態を維持し続けるのです。
セルフヒーリングを導入することで、企業は計り知れないメリットを享受できます。
自動復旧のメリット
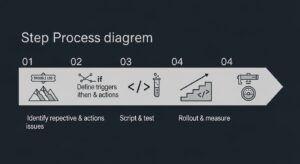
自動復旧の概念は理解できても、「具体的に何から始めればよいのか」と悩む方も多いでしょう。ここでは、効果的なセルフヒーリングを実現するための運用設計の基本ステップを解説します。
まずは、自動化の対象を明確にします。日々の運用業務を棚卸しし、自動化によって最も効果が見込める領域を見つけ出しましょう。
この作業を通じて、「自動化すべき業務」の優先順位を決定します。効果が大きく、かつ実現が容易なものから着手するのが成功の鍵です。
自動化対象が決まったら、具体的な「トリガー」と「アクション」の組み合わせを「If-Thenルール(もしAが起きたら、Bを実行する)」で定義します。
例えば、「WebサーバーのIISアプリケーションプールが停止(トリガー)したら、該当プールを再起動する(アクション)」といった具体的な構成を設計します。
定義したアクションを実行するためのスクリプト(PowerShell、Shellスクリプトなど)を作成します。多くのRMMツールにはテンプレートが用意されています。
重要なのは、必ず検証環境で十分にテストを行うことです。意図通りに動作するか、予期せぬ副作用がないかを確認しましょう。特にファイル削除などを伴うスクリプトは、慎重な検証が不可欠です。
テスト完了後、いよいよ本番環境へ導入します。一斉展開は避け、影響範囲の少ない一部のグループから適用する「スモールスタート」が推奨されます。
導入後は、自動復旧の実行回数や削減できた手動対応時間などを記録し、投資対効果(ROI)を測定します。この結果を基にシナリオを改善し、自動化の範囲を拡大していくことで、継続的な業務効率化のサイクルが生まれます。
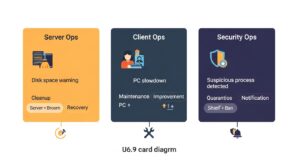
ここでは、サーバー運用、クライアントPC管理、セキュリティ対策の3つの観点から、すぐにでも応用できる具体的な自動復旧シナリオの事例を紹介します。
自動復旧の可能性を最大限に引き出すには、自社に合ったRMMツールを選ぶことが重要です。
RMMツール選定のポイント

本記事では、RMMを単なる監視ツールから脱却させ、プロアクティブなIT運用を実現するための自動復旧(セルフヒーリング)について解説しました。
障害発生後の事後対応に追われる「守りのIT運用」から、障害を未然に防ぎ、定型業務を自動化する「攻めのIT運用」へ。RMMの自動復旧機能は、その変革を実現するための強力な武器となります。
まずは、自社の運用業務の中で「最も時間を奪われている定型作業」や「繰り返し発生している障害」を一つ見つけ、その自動化から始めてみませんか?多くのRMMソリューションが無料トライアルを提供しています。小さな成功体験を積み重ねることが、組織全体の運用文化を変える大きな一歩となるはずです。
記載されている内容は2026年02月13日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
