
フォレンジックの成否は「時刻」で決まる:NTP時刻同期と改ざん防止ログ保存設計、SIEM活用まで徹底解説
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...
更新日:2026年02月10日
1分でわかるこの記事の要約 データ棚卸しは、膨大なデータの中から企業にとって本当に守るべき「本丸データ」を特定し、情報漏洩リスクを効率的に軽減する取り組みです。 「Fingerprinting」技術は、データ固有の指紋を […]
目次
現代のビジネス環境において、データは最も重要な資産の一つです。しかし、その管理はますます複雑化しており、新たなセキュリティ課題を生み出しています。なぜ今、改めてデータ棚卸しを行い、守るべき「本丸データ」を特定する必要があるのでしょうか。
企業が日々生成・保存するデータ量は爆発的に増加しています。特に、ファイルサーバーやクラウドストレージに保管されている「静止データ(Data-at-Rest)」は、管理者の目が届きにくく、情報漏洩の温床となりがちです。
実際に、不正アクセスや内部関係者による意図しない操作が原因で、機密情報や個人情報が外部に流出する事件は後を絶ちません。従来のファイアウォールなどに代表される境界型防御だけでは、巧妙化するサイバー攻撃や内部からのリスクに完全に対応することは困難です。このような状況下で、自社がどのような情報資産を保有し、どこにリスクが潜んでいるのかを正確に把握する「現状把握」の重要性が高まっています。
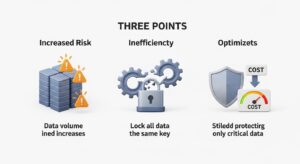
「すべてのデータを最高レベルで保護する」というアプローチは、理想的に聞こえるかもしれません。しかし、現実には膨大なコストと運用負荷を招き、持続可能ではありません。
重要度が低いデータにまで過剰なセキュリティ対策を施す一方で、本当に守るべき「本丸データ」や「コアデータ」への対策が手薄になってしまうリスクすらあります。結果として、策定したセキュリティポリシーが形骸化し、組織全体のセキュリティレベルが低下しかねません。効率的かつ効果的なリスク管理を実現するためには、データの価値を見極め、メリハリのある対策を講じることが不可欠です。
「本丸データ」特定による3つのメリット
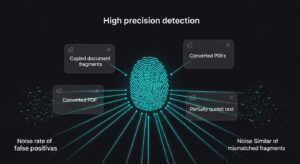
「本丸データ」を正確に特定し、保護するために極めて有効な技術が「Fingerprinting(フィンガープリンティング)」です。この技術は、従来のデータ検出方法が抱えていた課題を克服し、より高度なデータ管理を実現します。
Fingerprintingとは、保護対象としたいファイルの内容から、そのデータに固有の「指紋(フィンガープリント)」を生成・登録しておく技術です。この指紋は、ハッシュ値のようにデータ全体の特徴を捉えたユニークな識別子となります。
一度指紋を登録すれば、システムは社内のネットワークやストレージ上をスキャンし、登録された指紋と一致または類似するデータを発見できます。この技術の最大の特徴は、完全一致だけでなく、部分的に引用されたドキュメントや、フォーマットが変更されたファイルであっても、元となった重要データを高精度で検出できる点にあります。これにより、機密情報がコピー&ペーストされて別のファイルに含まれてしまった場合でも、その所在を突き止めることが可能になります。
従来の情報漏洩対策(DLP: Data Loss Prevention)では、正規表現や特定のキーワードに基づいて機密情報を検出する手法が一般的でした。しかし、この方法では「重要」という単語が含まれていない重要書類を検出できなかったり、逆に一般的な単語に過剰反応して誤検知が多発したりする課題がありました。
一方、Fingerprintingはデータの内容そのものを識別するため、誤検知が極めて少なく、より正確なデータ特定が可能です。例えば、キーワード検索では見逃してしまうような、定型フォーマットの契約書や複雑な設計図、個人情報を含むリストといった非構造化データでも、その内容を指紋として記憶させることで確実に検出できます。DLPとFingerprintingを組み合わせることで、ルールの網羅性と検出の正確性を両立させ、より強固なデータガバナンス体制を築くことができます。
これらのターゲットデータを指紋化しておくことで、意図しない場所への保存や不正な持ち出しをリアルタイムで検知し、情報漏洩を未然に防ぐセキュリティ対策を講じることが可能になります。
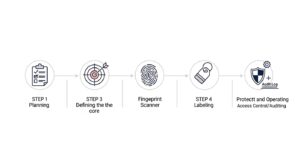
ここからは、Fingerprinting技術を実際に活用して、社内のデータ棚卸しを進めるための具体的な手順を5つのステップに分けて解説します。この手順に沿って進めることで、網羅的かつ効率的に本丸データの特定と保護を実現できます。
まず、データ棚卸しプロジェクトの土台を固めます。最初に、「何のためにデータ棚卸しを行うのか」という目的(情報漏洩対策、コンプライアンス対応など)を明確に設定します。
次に、棚卸しの対象範囲(全社のファイルサーバー、特定のクラウドストレージなど)を優先順位をつけて決定します。そして、情報システム部門、セキュリティ担当、法務、各事業部門の代表者などを巻き込み、責任者と役割分担を明確にした推進体制を構築することが成功の鍵です。最後に、情報資産管理台帳や棚卸しシートのテンプレートを準備し、プロジェクトを記録する準備を整えます。
次に、自社にとっての「本丸データ」とは何かを具体的に定義します。これは、企業の業種や事業内容によって異なり、例えば製造業なら設計図、金融業なら顧客の取引データなどが該当します。部門ごとにヒアリングを行い、「漏洩した場合に最も事業インパクトが大きいデータは何か」という観点で洗い出します。
定義ができたら、それを基にデータの分類基準を作成します。一般的には、機密性に応じて「極秘」「社外秘」「部内秘」「公開」といったレベル分けを行います。この際、「どのような情報が含まれれば『極秘』か」といった判断基準を明文化することが重要です。既存のセキュリティポリシーと整合性をとり、ISO 27001などを参考に策定すると、より客観的なものになります。
分類基準が定まったら、いよいよFingerprinting技術の出番です。Fingerprinting機能を搭載したデータ検出ツールを導入し、ステップ2で定義した「本丸データ」のサンプルを指紋として登録します。
その後、ステップ1で定めた対象範囲に対してスキャンを実行します。ツールは、広大なデータの中から、登録された指紋と一致・類似するデータを高速で検出します。多くのツールは「どこに、どのような重要データが、どれだけ存在し、誰がアクセスできるのか」をダッシュボードなどで可視化できます。これにより、これまで認識されていなかったリスク(例:不適切なアクセス権限)が明らかになります。
データ検出によって本丸データのありかが可視化されたら、次はその一つひとつに分類情報を付与していきます(データの分類)。ステップ3で検出されたデータに対し、ステップ2で作成した分類基準を適用し、「このファイルは極秘」といった仕分けを行います。
そして、分類結果に基づいてファイルに識別用の情報(メタデータ)を付与することを「データラベリング」と言います。このラベルは、後のアクセス制御のトリガーとなる重要な情報です。ツールの自動分類・ラベリング機能を活用すれば、Fingerprintingで検出されたデータに自動的に「極秘」ラベルを付与するといったルール設定が可能になり、作業を大幅に効率化できます。
データ棚卸しとラベリングの最終ゴールは、分類結果に基づいて適切なデータ保護を実施することです。付与されたラベル情報を基に、アクセス制御を強化します。例えば、「極秘」ラベルが付いたファイルには、特定の役職者しかアクセスできないように権限を設定したり、IRM(Information Rights Management)技術と連携してファイルの暗号化や印刷禁止といった操作制限をかけたりします。
また、データは日々変化するため、データ棚卸しは一度で終わりではありません。定期的なスキャンと監査を実施し、PDCAサイクルを回して管理体制を維持・向上させていくことが、持続的なデータ保護につながります。

理論や手順を理解しても、実際のプロジェクトを成功させるにはいくつかの壁が存在します。ここでは、データ棚卸しをスムーズに進めるための重要なポイントを3つ紹介します。
データ棚卸しは、情報システム部門だけでは完結できません。全社的な取り組みとなるため、経営層の強いリーダーシップとコミットメントが不可欠です。情報セキュリティは単なるコストではなく、事業継続性を支える重要な経営課題であるという認識を共有してもらいましょう。経営層の理解を得ることで、必要な予算や人員を確保しやすくなり、各部門への協力要請もスムーズに進みます。
最初から全社・全データを対象に完璧な棚卸しを目指すと、計画が壮大になりすぎて頓挫するリスクが高まります。まずは、最もリスクが高いと思われる部門や、特定のファイルサーバーなど、対象を絞ってスモールスタートを切ることをお勧めします。小さな範囲で成功事例を作り、それをモデルケースとして横展開していくアプローチが、結果的に最も着実な進め方です。
数テラバイトにも及ぶデータを手作業ですべて棚卸しすることは現実的ではありません。Fingerprinting機能を搭載したデータ検出・分類ツールや、CASBなどのソリューションを有効活用することがプロジェクトの成否を分けます。ツールを選定する際は、検出精度はもちろん、管理画面の使いやすさや自動化機能の充実度などを比較検討しましょう。適切なツールは、一連のプロセスを大幅に効率化し、担当者の負担を軽減します。

A1: 企業の規模、データ量、対象範囲によって大きく異なりますが、一般的には計画策定から初期の分類・ラベリング完了まで、数ヶ月単位の期間を見込むのが現実的です。特に、本丸データの定義や分類基準の策定には各部門との調整が必要なため、時間がかかることがあります。そのため、前述の通り、スモールスタートのアプローチを強く推奨します。
A2: はい、あります。代表的なものに、特定の文字列パターンを検出する「正規表現(例:マイナンバーの桁数)」や、事前に登録した「キーワード(例:”機密”)」による検索があります。これらの方法は特定の定型データには有効ですが、Fingerprintingは契約書や設計図といった非構造化データや、文脈に依存する機密情報を高い精度で特定できるという強みがあります。目的に応じてこれらの技術を使い分ける、あるいは組み合わせて使用することが重要です。
A3: はい、Excelで作成することは可能です。小規模な組織であれば、十分に機能する場合もあります。テンプレートには、情報資産名、保管場所、管理者、分類レベル、アクセス権などの項目を含めるとよいでしょう。ただし、データ量が多くなると管理が煩雑になり、更新漏れなどのリスクが高まるため、継続的かつ効率的な管理を目指すのであれば、専用ツールの利用を検討することをお勧めします。

本記事では、Fingerprinting技術を活用して、企業が本当に守るべき「本丸データ」を特定し、保護するためのデータ棚卸しの具体的な手順と成功のポイントを解説しました。
重要なのは、以下のステップを確実に実行することです。
情報漏洩のリスクは、もはや他人事ではありません。まずは自社の現状把握から始め、どのデータが「本丸データ」に該当するのか、チームや部署内でディスカッションすることから始めてみてはいかがでしょうか。それが、効率的で強固なデータ保護体制を築くための、確かな第一歩となるはずです。
記載されている内容は2026年02月10日時点のものです。現在の情報と異なる可能性がありますので、ご了承ください。また、記事に記載されている情報は自己責任でご活用いただき、本記事の内容に関する事項については、専門家等に相談するようにしてください。
1分でわかるこの記事の要約 サイバー攻撃調査において、ログの時刻同期がずれているとタイムライン分析が崩壊し、原因究明が困...

1分でわかるこの記事の要約 サイバー攻撃の再発防止には、目の前の暫定対処だけでなく、根本原因を取り除く恒久対応への転換が...

1分でわかるこの記事の要約 SOARによるセキュリティ自動化は強力ですが、封じ込め機能には「誤隔離」という重大なリスクが...

1分でわかるこの記事の要約 サイバーキルチェーンに基づくインシデント対応プレイブックは、サイバー攻撃の被害を最小化するた...

1分でわかるこの記事の要約 SIEM検知ルールはログ欠損や形式変更、陳腐化、プラットフォーム更新により機能不全に陥ります...

履歴書の「趣味特技」欄で採用担当者の心を掴めないかと考えている方もいるのではないでしょうか。ここでは履歴書の人事の...

いまいち難しくてなかなか正しい意味を調べることのない「ご健勝」「ご多幸」という言葉。使いづらそうだと思われがちです...

「ご査収ください/ご査収願いします/ご査収くださいますよう」と、ビジネスで使用される「ご査収」という言葉ですが、何...

選考で要求される履歴書。しかし、どんな風に書いたら良いのか分からない、という方も多いのではないかと思います。そんな...
通勤経路とは何でしょうか。通勤経路の届け出を提出したことがある人は多いと思います。通勤経路の書き方が良く分からない...
